
What Is The Need Of R For Data Science?
R is a programming language that also serves as a software environment for statistical analysis, graphics representation, and reporting. The R Development Core Team is currently working on R, which was created by Ross Ihaka and Robert Gentleman at the University of Auckland in New Zealand. As a result, it bears the names of both authors. R, as well as the pre-compiled binary versions for various operating systems such as Linux, Windows, and Mac, is freely available under the GNU General Public License. To learn more about R in detail, you should check out R for data science Tutorial.
Features Of R
R is a programming language as well as a software environment for statistical analysis, graphics representation, and reporting, as we previously discussed. R has several important features, which are listed below.
- R is a well-developed, simple, and powerful programming language that includes conditionals, loops, user-defined recursive functions, as well as input and output facilities.
- R has efficient data handling and storage methods.
R also has a diverse set of operators for performing calculations on arrays, lists, vectors, and matrices. - R also comes with a large, well-organized, and well-integrated set of data analysis tools.
- R provides a graphical interface for data analysis and display, which can be done directly on the computer or via printing on paper.
To summarise, R is the most widely used statistical programming language in the world. It’s the #1 choice of data scientists, and it’s backed up by a thriving and talented community of contributors. R is also taught in schools and then used in mission-critical business applications
What is Data Science?
Data Science is an interdisciplinary field that focuses on extracting knowledge and insights from data in various forms, including both structured and unstructured data, using scientific methods, processes, algorithms, and systems. Despite recent increases in computing power and data access over the last few years, we have lost our ability to use data in the decision-making process. If an organisation is having a problem, it should be able to use the data correctly to solve the problem. This is how data science functions. Let’s take a look at the data life cycle. This cycle consists of six steps:
1. Business Requirements
2. Data Acquisition
3. Data Processing
4. The Data Exploration
5. Data Modeling
6. Deployment
Step 1: Business Requirements
The data life cycle begins with this requirement. It is critical that we understand the problem we are trying to solve before we begin a data science project. We should also be identifying the central objectives of your project at this stage by identifying the various variables that must be predicted.
Step 2: Data Acquisition
This is the data life cycle’s second requirement. Now that we’ve established our project’s goals, it’s time to begin collecting the data we’ll need. Data mining is also known as the process of collecting information from various sources. Some of the questions we have at this point are worth considering, such as what data do I need for my project? What is its residence? What is the best way for me to get it? And, what is the most efficient method for storing and retrieving everything? These are a few of the questions that must be considered when collecting data.
Step 3: Data Wrangling (Cleaning)
This is the data life cycle’s third requirement. In general, we understand that finding the right data takes time and effort. If the required data is stored in a database, we are in a better position. However, if the information we require does not exist in a database, we will have to scrape it. This is where the data is transformed into the desired format so that it can be read. We’ll move on to the most time-consuming step of all: cleaning and preparing the data after we’ve imported all of the data. This procedure can consume up to 80% of our time. As a result, data cleaning can be defined as the process of removing irrelevant and inconsistent data. In this stage, the inconsistencies must be identified and corrected.
Step 4: Data Exploration
This is the data life cycle’s fourth requirement. The data exploration stage is where we should learn about the patterns in our data and extract all of the information we can from it. We should also start forming hypotheses about our data and look for hidden patterns. We can also use R to implement data visualisation packages like ggplot2 to gain a better understanding of the data.
Step 5: Data Modelling
This is the data life cycle’s fifth requirement. At this point, we must conduct model training. Splitting the data set into two sets, one for training and the other for testing is the first step in model training. The models must then be built using the training dataset. Machine learning algorithms such as K Nearest Neighbor, Support Vector Machine, Linear regression, and others are used in these models. The final step is to assess the models’ efficiency as well as their ability to predict outcomes accurately.
Step 6: Deployment
The Data cycle comes to a close with this step. The goal of this stage is to put the models into production or a similar environment for final user acceptance. This is where we must determine whether or not our model is suitable for production. Users must also validate the models’ performance, and any issues with the models must be addressed at this time.
What is R Programming for Data Science?
What is Data Science in R? It is a question that many of us have on our minds. What does R stand for in R programming, we wonder?
As a result, we can say that R is an open-source programming language as well as a statistical language for data analysis, data manipulation, and data visualisation. It’s also a general-purpose programming language that’s widely used in data science. Python and R are the two most common languages used in Data Science, as most of us are aware.
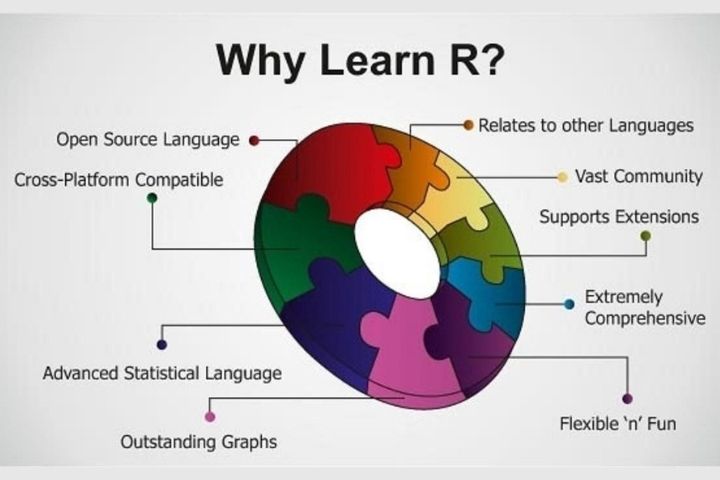
Here is why we should select R:
R is the statistical support R, which was created as a statistical language, and it shows. This is beneficial because statistics is an important part of Data Science. The state models package in Python covers statistical methods adequately, but the R ecosystem is much larger. The following are some of the reasons:
1. Data manipulation is number one.
We can easily shape the dataset into a format that can be easily accessed and analysed using R, which allows us to slice large multivariate datasets.
2. R has built-in data analysis functions.
The summary built-in function in R can be used to analyse summary statistics. In Python, we need to import packages like stats models to accomplish this.
3. Over 8000 packages
R has over 8000 packages that can be used to implement statistical analysis tools such as hypothesis testing, model fitting, clustering techniques, and machine learning.
4. Visualization of data
It is also necessary to visualise data to understand and comprehend a dataset and the relationships between various variables. Data Visualization helps in making insights from data. And R is capable of creating graphs and other data visualizations tools.
5. A large amount of community support
R is also the most popular technology due to its inventiveness and community support. It is used by over 2.5 million people. R is used by companies such as TechCrunch, Google, Facebook, Mozilla, and others.
Also Read : 8 Steps To Planning And Managing a Corporate Event

